


Technological progress and automation are starting to influence numerous spheres of human economy and everyday life. The rapid development of artificial intelligence imposes training computers to do the human work and implement their usage in business. One of the main applications of artificial intelligence in business is the chatbot.
In one of our recent articles, we spoke about the general principles of NLP and possible applications of chatbots. They have great potential in the area of customer service, and can easily accept the customer’s order and give them a consultation regarding the company’s services.
It is possible to automate the work of support centers with the help of bots on the official website of the company or in popular messengers like Telegram, Slack or Facebook Messenger.
In this article, we shall give you a brief tutorial about chatbot development, and share our experience in building a Telegram chatbot in Python.
Brief description of the project
Nowadays, NLP has become a topic of high importance since it makes sense of unstructured text data. It can be used in commerce, for example, and creating intelligent bots who can classify customers according to their requests, interests and characteristics, and handle millions of requests simultaneously.
Our project allows creating the chatbots who are able to analyze a real-time dialogue between the client and the consultant. It is possible to teach a bot in order to improve the quality of the answers and to train him to process more case-by-case situations.
Online consulting implies face-to-face consultation with the client and influence him as a potential buyer. In order to do this, the consultant should know the customer’s profile (interests, vocabulary, and psychological type). The majority of online dialogues is handled via phone calls or messages. The application has several libraries for understanding the human voice and transforming it into text data.
According to this, the idea of the project is building an interactive system capable of self-learning while communicating with the customers by classifying and processing their lexical forms. The main aim of our AI bot is to identify entity-clusters – groups of related entities. Entity-clusters can be very useful for many activities. For example, we can analyze customer requests and identify or even sort them by interests groups.
Technological stack
Frontend:
- Javascript programming language;
- JSON objects visualizer JSON schema viewer;
- Frontend framework Twitter (Facebook) Bootstrap;
- SocketIO for real-time client-server connection.
Choice of technologies
The project’s architecture is based on Telegram and its backend part written in Python programming language. Since the web-client is the main component of the project, one of the most important decisions was to choose the suitable framework for the realization of the web-application. There are several “full-stack” frameworks for Python language: Django, Grok, web2py, Giotto.
The application is written in Python programming language in order to unite the process of development and machine learning. Django and Web2py frameworks were chosen for the development. In order make a Telegram bot and integrate it with Telegram services, Telegram Bot API was used.
In order to realize the AI part of the project, the following Python libraries were used:
- NumPy – a library that supports large multidimensional arrays and matrices.
- SciPy (Scikit-learn) – an open-source library of scientific instruments for Python programming languages containing modules for optimization and genetic algorithms.
- NLPK library – set of libraries and programs on Python for symbol and statistical natural language processing.
- Gensim Python library – a popular tool for automatic language processing based on machine learning. In this library, clusterization and distributed semantics algorithms (word and doc) are realized. It allows one to solve the problems of topic modeling and distinguish the main topics of a text or a document.
- Scrapy – one of the most productive Python libraries for receiving the data from web-pages.
The key point in choosing the tools is selecting the library for machine learning. In terms of morphological analysis, we decided to choose a Pyromorphy2 one. TeleBot library was chosen for using of Telegram Bot API. The client-side realization of web sockets is handled via SocketIO library. Flask-SocketIO library is used for establishing a real-time client-server communication. It is a tool for using a SocketIO library in connection with Flask – a convenient framework for working with web-sockets.
Databases
In order to create an AI-based bot, it is necessary to use the database of questions and answers. The time gap between the client’s inquiry and the bot’s reply should be as small as possible. In order to achieve this goal, we decided to choose Redis – a highly productive non-relational database. The information about questions and answers is stored as blocks of messages from the conversation. The advantages of such approach are:
- It allows one to conveniently find the necessary elements of the records.
- By using this way of storing the data, it is possible to record dialogues of any length without any restriction in the number of the fields or keys in the hash-table.
Since the main goal of the development was creating a real-time application, web-sockets technology was used. They will imply the interactive connection allowing real-time client-server interaction. In contrast to HTTP/HTTPS, web-sockets are able to work with bidirectional flow that will hasten the work of the application. They will be useful for creating any type of real-time software: chatbots, IoT-applications or multiplayer online game.

Implementation of machine learning
Choosing a suitable algorithm of machine learning is an important point in the development of any intellectual system. All the algorithms of machine learning can be subdivided into three types:
- Controlled learning is used if there is a block of data with particular obvious properties that are not clear for another block, and it is necessary to predict them while working.
- Uncontrolled learning is used for finding out the implicit relation in the unmarked set of data.
- Reinforced learning is a symbiosis of the aforementioned categories and implies the presence of some particular type of feedback that is available for every step or action when there are no markup or error messages.
One of the tasks of the project is the classification of the answers according to the questions from databases. The answers were classified in terms of their relation to the corresponding category.
Machine learning was handled with the help of the decision trees. One of them was substituted for the random forest. It is a set of several trained trees that handle the voting. Based on its results, the random forest prepares the reply according to the specified selection. For the realization of choosing the suitable one, the enforcement graph memo was used. It is a model designed by Microsoft that is used for selecting the machine learning algorithm for particular tasks (see the picture below).
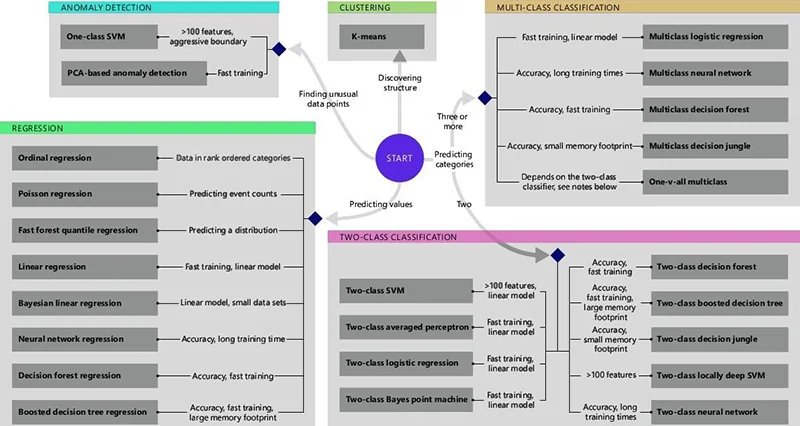
Based on the scheme, we come to the conclusion that the random forest algorithm is the most suitable one for solving the tasks of multiclass classification when precision and speed of learning are of the highest priority.
The bot training process
The process of bot learning consists of several stages:
- Dialogue database pre-processing – after this stage is completed, only those sets that correspond to the current stage of the dialogue are left.
- Selecting the questions – having completed the previous stage, the system creates the core for learning. Before this stage, the text of each question is reduced to common form. Additionally, all the words are normalized with the help of morphological analyzer Pymorphy2. In this way, each word is returned to its initial form, and the participle is reduced to the infinitive. It allows processing the same words in the same way, notwithstanding the different context.
- Creating the TF-IDF vectorizer for a normalized selection of the questions – the processing of the whole database of questions and learning of the random forest is based on the vectorizer.

The workflow of the application
The application consists of a web-client and a Telegram chatbot on Python. The main functions of the application are:
- Real-time processing of client’s messages
- Providing the possible variants for bot’s replies
- Real-time processing of bot’s decision and sending the reply to the client
The web-client consists of the interface for the work of the dialogue graph and of the keyboard for sending the messages. The client-side interaction with the bot is the classical option of working with the Telegram bot. Upon launching the application, two flows are launched as well. One of them is to maintain the work of Telegram bot, and the second one – the work of application. Processing of the client’s messages is handled through the tools “message handler” of TeleBot library.

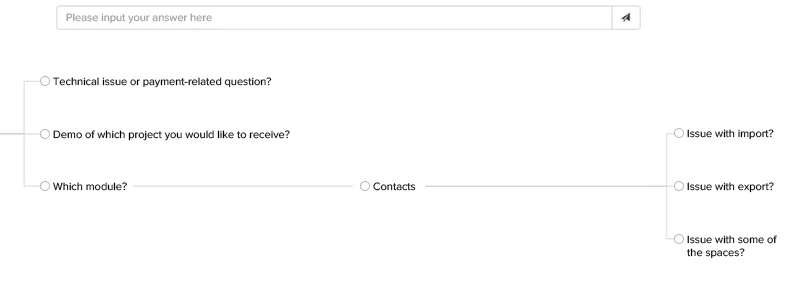
At the head of the graph, the user’s question and the possible options for the answer are located. Upon clicking on one of the answers, its text is automatically displayed in the space of the answer.
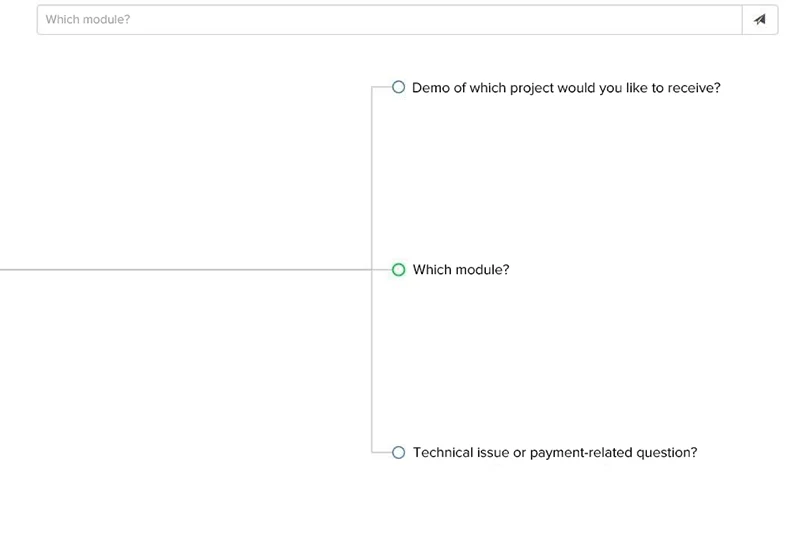
Then, the system is waiting for the client’s reply to the sent message. When it receives it, the graph is reorganized by adding the user’s answer to the branch with the selected messages. New replies are prepared by the application.
The main challenges of the project
While working on the project, we faced the following challenges:
- Implementing real-time processing of the customers’ messages
- Real-time introduction of possible variants of consultant’s answers
- Real-time processing of consultant’s decision and sending the reply to the customer
- Dynamic extending of dialogues database while the system is working
In order to solve these challenges, we implemented the following features:
- Pre-processing of the client’s answers – creating a frequency matrix of the vocabulary for finding out of the most frequently used words.
- Searching for sense clusters uniting the words with similar meaning with the help of a self-organizing map (SOM). This is a type of artificial neural network that is trained to produce a low-dimensional (typically two-dimensional), discretized representation of the input space of the training samples, called a map. Self-organizing maps differ from other artificial neural networks as they apply competitive learning as opposed to error-correction learning.
- Using Redis for data storage with the possibility of quick processing of the queries.
Conclusion
Although intellectual systems are growing rapidly, it is only the beginning of their implementation in the sphere of consulting. This is because of the necessity of the real-time handling of the online consultation, and because the algorithms of machine learning demand a lot of time for preprocessing and the learning itself.
Here at Sloboda Studio, we can help you to develop a Telegram chatbot using Python. Our specialists will thoroughly analyze your business model and develop the solution that will perfectly satisfy the needs of your business. Should you have any questions – we are always here to help!



