Der technologische Fortschritt und die Automatisierung beginnen, zahlreiche Bereiche der menschlichen Wirtschaft und des täglichen Lebens zu beeinflussen. Die rasante Entwicklung der künstlichen Intelligenz führt dazu, dass Computer die menschliche Arbeit übernehmen und in der Wirtschaft eingesetzt werden. Eine der wichtigsten Anwendungen von künstlicher Intelligenz in der Wirtschaft ist der Chatbot.
In einem unserer letzten Artikel haben wir über die allgemeinen Prinzipien von NLP und mögliche Anwendungen von Chatbots gesprochen. Sie haben ein großes Potenzial im Bereich des Kundendienstes und können problemlos die Bestellung des Kunden annehmen und ihn zu den Dienstleistungen des Unternehmens beraten.
Es ist möglich, die Arbeit von Supportzentren mit Hilfe von Bots auf der offiziellen Website des Unternehmens oder in beliebten Messengern wie Telegram, Slack oder Facebook Messenger zu automatisieren.
In diesem Artikel geben wir Ihnen eine kurze Einführung in die Chatbot-Entwicklung und teilen unsere Erfahrungen mit der Erstellung eines Telegram-Chatbots in Python.
Kurze Beschreibung des Projekts
Heutzutage ist NLP ein sehr wichtiges Thema, da es unstrukturierte Textdaten verständlich macht. Es kann z. B. im Handel eingesetzt werden, um intelligente Bots zu erstellen, die Kunden nach ihren Wünschen, Interessen und Eigenschaften klassifizieren und Millionen von Anfragen gleichzeitig bearbeiten können.
Unser Projekt ermöglicht die Erstellung von Chatbots, die in der Lage sind, einen Dialog zwischen dem Kunden und dem Berater in Echtzeit zu analysieren. Es ist möglich, einen Bot zu unterrichten, um die Qualität der Antworten zu verbessern und ihn zu trainieren, mehr Einzelfälle zu bearbeiten.
Online-Beratung bedeutet, mit dem Kunden persönlich zu sprechen und ihn als potenziellen Käufer zu beeinflussen. Dazu sollte der Berater das Profil des Kunden kennen (Interessen, Wortschatz und psychologischer Typ). Der Großteil der Online-Dialoge wird über Telefonanrufe oder Nachrichten abgewickelt. Die Anwendung verfügt über mehrere Bibliotheken, um die menschliche Stimme zu verstehen und sie in Textdaten umzuwandeln.
Dementsprechend besteht die Idee des Projekts darin, ein interaktives System zu schaffen, das in der Lage ist, selbst zu lernen, während es mit den Kunden kommuniziert, indem es ihre lexikalischen Formen klassifiziert und verarbeitet. Das Hauptziel unseres KI-Bots ist die Identifizierung von Entity-Clustern – Gruppen von verwandten Entitäten. Entity-Cluster können für viele Aktivitäten sehr nützlich sein. Zum Beispiel können wir Kundenanfragen analysieren und sie nach Interessengruppen identifizieren oder sogar sortieren.
Technologischer Stapel
Frontend:
- Javascript Programmiersprache;
- Visualisierung von JSON-Objekten JSON-Schema-Viewer;
- Frontend-Framework Twitter (Facebook) Bootstrap;
- SocketIO für Echtzeit-Client-Server-Verbindung.
Auswahl der Technologien
Die Architektur des Projekts basiert auf Telegram und der Backend-Teil ist in der Programmiersprache Python geschrieben. Da der Web-Client die Hauptkomponente des Projekts ist, war eine der wichtigsten Entscheidungen die Wahl des geeigneten Frameworks für die Realisierung der Web-Anwendung. Es gibt mehrere „Full-Stack“-Frameworks für die Sprache Python: Django, Grok, web2py, Giotto.
Die Anwendung ist in der Programmiersprache Python geschrieben, um den Prozess der Entwicklung und des maschinellen Lernens zu vereinen. Für die Entwicklung wurden die Frameworks Django und Web2py gewählt. Um einen Telegram-Bot zu erstellen und ihn in die Telegram-Dienste zu integrieren, wurde die Telegram Bot API verwendet.
Um den KI-Teil des Projekts zu realisieren, wurden die folgenden Python-Bibliotheken verwendet:
- NumPy – eine Bibliothek, die große multidimensionale Arrays und Matrizen unterstützt.
- SciPy (Scikit-learn) – eine Open-Source-Bibliothek mit wissenschaftlichen Instrumenten für die Programmiersprache Python, die Module für Optimierung und genetische Algorithmen enthält.
- NLPK-Bibliothek – eine Reihe von Bibliotheken und Programmen auf Python für Symbol- und statistische natürliche Sprachverarbeitung.
- Gensim Python-Bibliothek – ein beliebtes Werkzeug für die automatische Sprachverarbeitung auf der Grundlage des maschinellen Lernens. In dieser Bibliothek sind Algorithmen zur Clusterisierung und verteilten Semantik (Word und Doc) realisiert. Sie ermöglicht es, die Probleme der Themenmodellierung zu lösen und die Hauptthemen eines Textes oder eines Dokuments zu unterscheiden.
- Scrapy – eine der produktivsten Python-Bibliotheken für den Empfang von Daten aus Webseiten.
Der wichtigste Punkt bei der Auswahl der Tools ist die Auswahl der Bibliothek für maschinelles Lernen. Im Hinblick auf die morphologische Analyse haben wir uns für Pyromorphy2 entschieden. Die TeleBot-Bibliothek wurde für die Nutzung der Telegram Bot API gewählt. Die clientseitige Realisierung von Web-Sockets wird über die SocketIO-Bibliothek abgewickelt. Die Flask-SocketIO-Bibliothek wird für den Aufbau einer Echtzeit-Client-Server-Kommunikation verwendet. Es handelt sich um ein Tool zur Nutzung der SocketIO-Bibliothek in Verbindung mit Flask – einem komfortablen Framework für die Arbeit mit Web-Sockets.
Datenbanken
Um einen KI-basierten Bot zu erstellen, ist es notwendig, eine Datenbank mit Fragen und Antworten zu verwenden. Die Zeitspanne zwischen der Anfrage des Kunden und der Antwort des Bots sollte so gering wie möglich sein. Um dieses Ziel zu erreichen, haben wir uns für Redisentschieden – eine hochproduktive nicht-relationale Datenbank. Die Informationen über Fragen und Antworten werden als Nachrichtenblöcke aus der Konversation gespeichert. Die Vorteile eines solchen Ansatzes sind:
- Es ermöglicht ein bequemes Auffinden der notwendigen Elemente der Datensätze.
- Durch diese Art der Datenspeicherung ist es möglich, Dialoge beliebiger Länge ohne Beschränkung der Anzahl der Felder oder Schlüssel in der Hash-Tabelle aufzuzeichnen.
Da das Hauptziel der Entwicklung die Erstellung einer Echtzeitanwendung war, wurde die Web-Sockets-Technologie verwendet. Sie ermöglichen eine interaktive Verbindung, die eine Echtzeit-Interaktion zwischen Client und Server ermöglicht. Im Gegensatz zu HTTP/HTTPS sind Web-Sockets in der Lage, mit bidirektionalem Fluss zu arbeiten, was die Arbeit der Anwendung beschleunigt. Sie sind nützlich für die Erstellung jeder Art von Echtzeit-Software: Chatbots, IoT-Anwendungen oder Multiplayer-Online-Spiele.

Implementierung von maschinellem Lernen
Die Wahl eines geeigneten Algorithmus des maschinellen Lernens ist ein wichtiger Punkt bei der Entwicklung eines jeden intellektuellen Systems. Alle Algorithmen des maschinellen Lernens können in drei Typen unterteilt werden:
- Kontrolliertes Lernen wird verwendet, wenn es einen Datenblock mit bestimmten offensichtlichen Eigenschaften gibt, die für einen anderen Block nicht eindeutig sind, und es notwendig ist, diese während der Arbeit vorherzusagen.
- Unkontrolliertes Lernen wird verwendet, um die implizite Beziehung in einer unmarkierten Datenmenge herauszufinden.
- Verstärktes Lernen ist eine Symbiose der oben genannten Kategorien und impliziert das Vorhandensein einer bestimmten Art von Feedback, das für jeden Schritt oder jede Aktion verfügbar ist, wenn keine Markierungen oder Fehlermeldungen vorhanden sind.
Eine der Aufgaben des Projekts ist die Klassifizierung der Antworten zu den Fragen aus Datenbanken. Die Antworten wurden in Bezug auf ihre Beziehung zur entsprechenden Kategorie klassifiziert.
Das maschinelle Lernen wurde mit Hilfe von Entscheidungsbäumen durchgeführt. Einer von ihnen wurde durch den Zufallswald ersetzt. Dabei handelt es sich um eine Gruppe von mehreren trainierten Bäumen, die die Abstimmung durchführen. Auf der Grundlage seiner Ergebnisse bereitet der Zufallswald die Antwort entsprechend der vorgegebenen Auswahl vor. Für die Auswahl des geeigneten Baums wurde das Enforcement Graph Memo verwendet. Dabei handelt es sich um ein von Microsoft entwickeltes Modell, das für die Auswahl des maschinellen Lernalgorithmus für bestimmte Aufgaben verwendet wird (siehe Abbildung unten).
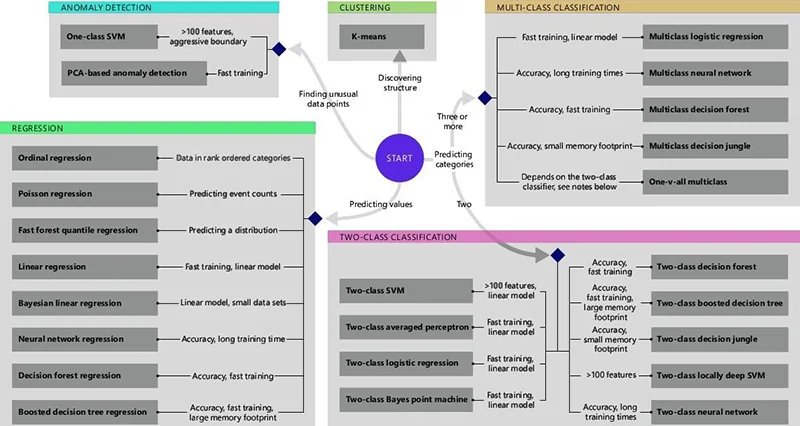
Auf der Grundlage des Schemas kommen wir zu dem Schluss, dass der Random-Forest-Algorithmus am besten geeignet ist, um die Aufgaben der Multiklassenklassifizierung zu lösen, wenn Präzision und Lerngeschwindigkeit höchste Priorität haben.
Der Bot-Trainingsprozess
Der Prozess des Bot-Lernens besteht aus mehreren Stufen:
- Vorverarbeitung der Dialogdatenbank – nach Abschluss dieser Phase bleiben nur die Sätze übrig, die der aktuellen Phase des Dialogs entsprechen.
- Auswahl der Fragen – nach Abschluss der vorangegangenen Phase erstellt das System den Kern für das Lernen. Vor dieser Phase wird der Text jeder Frage auf eine allgemeine Form reduziert. Außerdem werden alle Wörter mit Hilfe des morphologischen Analysators Pymorphy2 normalisiert, d.h. jedes Wort wird in seine ursprüngliche Form zurückgeführt, und das Partizip wird zum Infinitiv reduziert. Auf diese Weise können dieselben Wörter ungeachtet des unterschiedlichen Kontexts auf dieselbe Weise verarbeitet werden.
- Erstellung des TF-IDF-Vektorisierers für eine normalisierte Auswahl der Fragen – die Verarbeitung der gesamten Fragendatenbank und das Lernen des Random Forest basieren auf dem Vektorisierer.

Der Arbeitsablauf der Anwendung
Die Anwendung besteht aus einem Web-Client und einem Telegram-Chatbot auf Python. Die Hauptfunktionen der Anwendung sind:
- Echtzeit-Verarbeitung der Nachrichten des Kunden
- Bereitstellung der möglichen Varianten für die Antworten des Bots
- Echtzeit-Verarbeitung der Bot-Entscheidung und Senden der Antwort an den Kunden
Der Web-Client besteht aus der Schnittstelle für die Arbeit des Dialoggraphen und der Tastatur für das Senden der Nachrichten. Die clientseitige Interaktion mit dem Bot ist die klassische Möglichkeit der Arbeit mit dem Telegram-Bot. Beim Starten der Anwendung werden auch zwei Abläufe gestartet. Der eine dient dazu, die Arbeit des Telegram-Bots aufrechtzuerhalten, und der zweite – die Arbeit der Anwendung. Die Verarbeitung der Nachrichten des Clients wird durch die Tools „message handler“ der TeleBot-Bibliothek durchgeführt.

An der Spitze des Diagramms befinden sich die Frage des Benutzers und die möglichen Antwortoptionen. Wenn Sie auf eine der Antworten klicken, wird der Text automatisch im Feld der Antwort angezeigt.
Dann wartet das System auf die Antwort des Kunden auf die gesendete Nachricht. Sobald es diese erhält, wird das Diagramm umstrukturiert, indem die Antwort des Benutzers dem Zweig mit den ausgewählten Nachrichten hinzugefügt wird. Neue Antworten werden von der Anwendung vorbereitet.
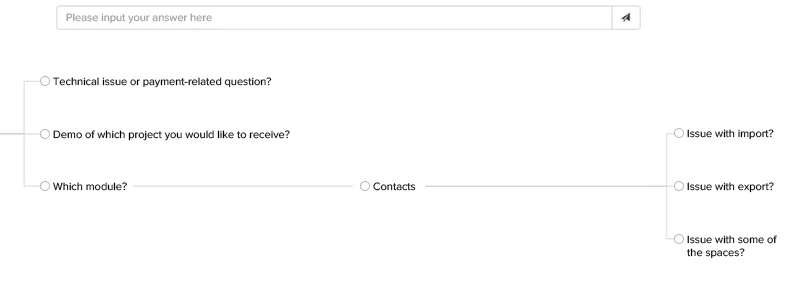
Die wichtigsten Herausforderungen des Projekts
Während der Arbeit an dem Projekt sahen wir uns mit den folgenden Herausforderungen konfrontiert:
- Implementierung der Echtzeitverarbeitung von Kundennachrichten
- Echtzeit-Einführung möglicher Varianten der Antworten des Beraters
- Echtzeit-Verarbeitung der Entscheidung des Beraters und Senden der Antwort an den Kunden
- Dynamische Erweiterung der Datenbank der Dialoge während des Betriebs des Systems
Um diese Herausforderungen zu lösen, haben wir die folgenden Funktionen implementiert:
- Vorverarbeitung der Antworten des Kunden – Erstellung einer Häufigkeitsmatrix des Vokabulars, um die am häufigsten verwendeten Wörter herauszufinden.
- Suche nach Sinnclustern, die die Wörter mit ähnlicher Bedeutung mit Hilfe einer selbstorganisierenden Karte (SOM) zusammenfassen. Dabei handelt es sich um eine Art künstliches neuronales Netz, das so trainiert wird, dass es eine niedrigdimensionale (in der Regel zweidimensionale), diskretisierte Darstellung des Eingaberaums der Trainingsmuster, eine so genannte Karte, erzeugt . Selbstorganisierende Karten unterscheiden sich von anderen künstlichen neuronalen Netzen, da sie kompetitives Lernen im Gegensatz zum Fehlerkorrekturlernen anwenden .
- Verwendung von Redis zur Datenspeicherung mit der Möglichkeit einer schnellen Verarbeitung der Abfragen.
Schlussfolgerung
Obwohl intellektuelle Systeme ein schnelles Wachstum verzeichnen, steht ihre Implementierung im Bereich der Beratung erst am Anfang. Das liegt zum einen an der Notwendigkeit, die Online-Beratung in Echtzeit abzuwickeln, und zum anderen daran, dass die Algorithmen des maschinellen Lernens viel Zeit für die Vorverarbeitung und das Lernen selbst benötigen.
Hier bei Sloboda Studio können wir Ihnen helfen, einen Telegram Chatbot mit Python zu entwickeln . Unsere Spezialisten werden Ihr Geschäftsmodell gründlich analysieren und eine Lösung entwickeln, die perfekt auf die Bedürfnisse Ihres Unternehmens abgestimmt ist. Sollten Sie noch Fragen haben – wir sind immer für Sie da!